Comparaison entre la performance du modèle et celle des 24 chirurgiens BMF pour l’ensemble de données de test. Les écarts moyens quadratiques (moustaches) ont été calculés par une analyse jackknife. La courbe représentant un F1-Score constant de 0,58 est utilisée pour comparer les résultats de performance de la figure 3. (Photo : Michael G. Endres)
1. Introduction :
Les radiographies panoramiques dentaires (RPD) sont un outil diagnostique courant et une modalité d’imagerie standard qui est souvent utilisée dans la routine clinique par les chirurgiens-dentistes et les chirurgiens buccaux et maxillo-faciaux (BMF).(1, 3) Bien que, dans certains cas, l’évaluation des RPD puisse être confiée à des radiologues, les chirurgiens BMF lisent souvent eux-mêmes leurs propres radiographies.
Une recherche antérieure a montré que la formation du praticien joue un rôle essentiel dans l’interprétation correcte de l’imagerie médicale.(4) Dans le domaine dentaire particulièrement, les variations du pourcentage de concordance (une approximation de la performance diagnostique) entre les évaluations radiologiques des professionnels de la santé bucco-dentaire semblent être en partie dues aux connaissances, compétences et subjectivités individuelles.(5, 6) La variabilité des aptitudes des professionnels de la santé bucco-dentaire à la lecture des RPD ouvre toute grande la porte au mauvais diagnostic ou au traitement inapproprié.(7, 8)
Par exemple, une recherche récente a montré que le pourcentage de mauvais diagnostic de la profondeur des caries basé sur la lecture d’une radiographie classique par les chirurgiens-dentistes s’élevait à 40 pour cent, et dans 20 pour cent des cas, le diagnostic de pathologie dentaire était erroné. (9, 10)
Dans le secteur médical, une recherche très récente a porté sur le développement d’outils diagnostiques et thérapeutiques utilisant l’intelligence artificielle (AI) pour étayer le processus de prise de décision clinique.(11, 14) Jusqu’à présent, l’AI a été introduite et utilisée dans de nombreux domaines cliniques tels que la radiologie,(12, 15, 16) la pathologie,(17–19) la dermatologie (20) et l’ophtalmologie (21,22) pour faciliter la détection d’une maladie et la formulation des recommandations subséquentes sur les options de traitement. Des algorithmes d’intelligence artificielle ont également été développés pour la segmentation d’images médicales à des fins thérapeutiques, telles que la délinéation des tumeurs de la tête et du cou permettant un meilleur ciblage de la radiothérapie.(23) Les recherches antérieures sur les diagnostics assistés par ordinateur en dentisterie et chirurgie BMF sont limitées. Ces études portaient sur la détection des caries au moyen des radiographies rétrocoronaires ainsi que sur la segmentation des dents et les calculs d’ancrages orthodontiques.(24–27) Le seul outil actuellement approuvé par la FDA (Food and Drug Administration) des États-Unis, le logiciel Logicon Caries Detector, a été introduit en 1998, et il ne sert qu’à la détection et au diagnostic précis de la profondeur des lésions carieuses interproximales.(28)
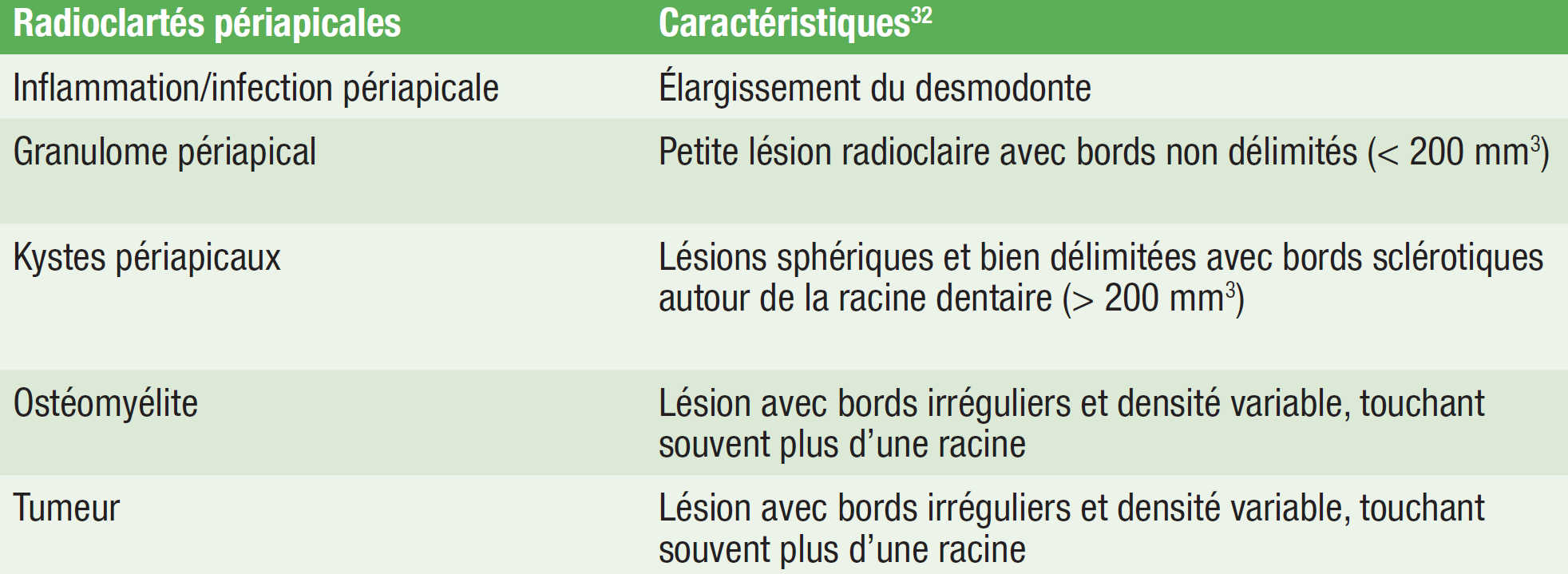
La détection des radio-clartés sur un RPD est une tâche courante pour les chirurgiens BMF.(29) En fait, la prévalence des radio-clartés péri-apicales sur les images radiographiques obtenues dans les services dentaires de consultation externe est approximativement de neuf à dix pour cent.(29–31) La présence de radio-clartés péri-apicales peut refléter des pathologies anodines ou graves des dents, notamment une infection (environ 55 à 70 % des radio-clartés), un kyste (25 à 40 % des radio-clartés), un granulome (1 à 2 % des radio-clartés) et une tumeur.(29–31) Le diagnostic tardif de ces radio-clartés péri-apicales peut mener à une propagation de la pathologie aux tissus adjacents, à des complications et à un état morbide chez les patients. (32) Bien que de nombreux chirurgiens-dentistes et chirurgiens BMF lisent eux-mêmes leurs RPD, très peu de recherches ont été menées pour évaluer leur précision pour identifier les radio-clartés péri-apicales.
Dans cette étude, nous avons évalué la détection des radio-clartés péri-apicales sur les RPD. Nous avons examiné la compétence des chirurgiens BMF à identifier la présence de ces radio-clartés sur les RPD. De plus, nous avons fait appel à l’apprentissage profond pour développer un algorithme analytique d’images susceptible de contribuer à la détection des radio-clartés péri-apicales sur les POG dans les cabinets dentaires, et nous avons comparé sa performance avec celle des chirurgiens BMF.
2. Matériel et méthodes
Les images utilisées dans cette étude proviennent des consultations externes du service de chirurgie buccale et maxillo-faciale, hôpital Charité, Berlin. Dans ce service de chirurgie buccale et maxillo-faciale, hôpital Charité, Berlin, les RPD représentent la modalité d’imagerie standard en raison de leur excellente capacité diagnostique globale discriminatoire. Cette modalité donne en outre une bonne vue d’ensemble grâce à l’évaluation de toutes les dents et des structures osseuses environnantes tout en minimisant les doses de rayonnement.(33–35)
Néanmoins, en radiologie endodontique, la norme générale de détection des radio-clartés périapicales, particulièrement en ce qui concerne le diagnostic de parodontite apicale, est toujours la radiographie péri-apicale.(33)
L’utilisation des images et la participation des chirurgiens BMF dans cette étude ont été approuvées par le comité d’éthique de la recherche de l’université Harvard (numéro de référence du comité : IRB17-0456 ; date d’approbation : 1er mai 2018 et de l’hôpital Charité, Berlin (numéro de référence du comité : EA2/030/18 ; date d’approbation : 15 mars 2018). Le consentement éclairé a été obtenu chez tous les chirurgiens BMF qui participaient à l’étude. Tous les procédés et tests ont été réalisés conformément aux lignes directrices et réglementations applicables (Déclaration d’Helsinki). L’annotation de tous les RPD a été effectuée dans des salles de radiologie standardisées comprenant un système de surveillance radiologique clinique connecté au système d’information informatisé de l’hôpital. Tous les chirurgiens BMF participants ont annoté les images par l’intermédiaire d’une application Web développée pour cette étude.
2.1. Évaluation de la fiabilité des diagnostics établis par les chirurgiens BMF quant à la présence de radio-clartés péri-apicales sur les RPD
Pour l’évaluation de la fiabilité des diagnostics de présence de radio-clartés péri-apicales sur les RPD lus par les chirurgiens BMF dans le cadre de la routine clinique, nous avons recruté (24) chirurgiens BMF (dix-huit dans le service de chirurgie buccale et maxillo-faciale, hôpital Charité, Berlin, trois dans le service de chirurgie buccale et maxillo-faciale, hôpital universitaire de Hambourg, Eppendorf, et trois dans des cabinets dentaires privés pratiquant la chirurgie BMF). Ces chirurgiens BMF représentaient un échantillon aléatoire comprenant treize internes et onze praticiens traitants (six femmes et dix-huit hommes).
Les chirurgiens BMF ont été chargés d’annoter 102 RPD anonymisés quant à la présence de radio-clartés péri-apicales cliniquement pertinentes (Tableau 1). Les caractéristiques servant de référence pour ces RPD avaient été établies par un chirurgien BMF indépendant de l’étude, possédant sept années d’expérience, qui avait traité les 102 patients associés à ces radiographies selon le protocole suivant : en premier lieu, prise et évaluation d’un RPD de la denture du patient, puis enregistrement de toutes les radio-clartés détectées ; en second lieu, examen de chaque dent du patient pour détecter des pathologies péri-apicales cliniquement pertinentes (p. ex., un abcès) à l’aide d’un test de vitalité pulpaire comprenant des tests thermiques et de percussion – une référence absolue de validation clinique de pathologies périapicales.(7) En général, contrairement aux dents saines, les dents atteintes d’une pathologie péri-apicale ne répondent à aucune méthode de test en raison de la perte de vitalité pulpaire. Par conséquent, plutôt que de se fier à la seule radiographie, le chirurgien BMF possédait des indices supplémentaires sur la probabilité que la radio-clarté péri-apicale soit un artéfact ou soit associée à une pathologie.
Tableau 1 : Description détaillée des lésions évaluées dans l’étude. .
Lorsqu’une radio-clarté n’avait pas été remarquée par le chirurgien BMF mais qu’une pathologie péri-apicale était ensuite détectée par le test clinique, l’image radiographique était évaluée une seconde fois pour déterminer si la radio-clarté péri-apicale était visible ou pas, puis elle était enregistrée.
2.2. Développement d’un algorithme d’apprentissage profond pour la détection automatique de radio-clartés péri-apicales sur les RPD
Nous avons développé notre modèle par une approche d’apprentissage supervisé, où la relation fonctionnelle entre l’entrée (c.-à-d., les images radiographiques) et le résultat en sortie (c.-à-d., une liste des sites de radio-clarté péri-apicale, et les scores de confiance correspondants) est « apprise » par entraînement sur des exemples fournis de données (images) annotées. Le processus requiert généralement plusieurs ensembles de données annotées : un ensemble de données utilisé pour les besoins de l’entraînement du modèle, un ensemble de données de validation utilisé pour déterminer si le modèle a fait l’objet d’un surapprentissage des données d’entraînement et pour sélectionner le meilleur modèle parmi plusieurs candidats, et un ensemble de données de test utilisé pour l’évaluation finale du modèle sélectionné. Nous avons évalué notre modèle en comparant sa performance sur les mêmes 102 images annotées par les 24 chirurgiens BMF décrits dans la Section 1 de « Matériel et méthodes ».
2.3 Images radiographiques et annotations pour l’entraînement du modèle.
L’ensemble de données d’entraînement, comprenant 3 240 images radiographiques, a été annoté par quatre chirurgiens BMF du même service des consultations externes (expérience allant de cinq à vingt années) en chirurgie buccale et maxillo-faciale, hôpital Charité, Berlin. Ils ont évalué visuellement les images, exemptes de toute information annotée les contours de toutes les radio-clartés péri-apicales visibles et traitables qu’ils avaient identifiées (Tableau 1). Il convient de remarquer qu’en Allemagne, les praticiens qui entament le programme d’internat en chirurgie BMF possèdent déjà au moins deux années d’expérience en lecture des radiographies dentaires et en traitement de patients dans le cadre d’un programme suivi en chirurgie dentaire. De plus, en Allemagne, une formation en radiologie dento-maxillofaciale fait partie intégrante du programme d’internat en chirurgie BMF. Aucune sous-spécialité en radiologie BMF n’existe en Allemagne.
Parmi les 3 240 images évaluées, 338 ont été exclues de l’ensemble de données d’entraînement. Les critères d’exclusion étaient une visibilité inappropriée de l’anatomie due à un mauvais positionnement ou à des artéfacts, une faible densité et un contraste insuffisant entre l’émail et la dentine, ainsi qu’une faible densité et un contraste insuffisant entre la dent et le tissu osseux périphérique.
Ces critères sont conformes aux normes décrites dans la littérature.(5, 36) La figure 1 présente la répartition des radio-clartés péri-apicales sur les 2 902 autres images annotées, et parmi les images retenues, 872 ont été jugées exemptes de radio-clartés visibles.
Fig. 1 : Répartition par image des radioclartés périapicales pour l’ensemble de données.
Fig. 2 : Exemples d’RPD (prétraités pour l’entrée du modèle) sélectionnés à partir de l’ensemble de données de test et superposés aux contours des données de vérité terrain (Ground Truth), la carte d’intensité en sortie produite par notre modèle (Model Output) et les sites obtenus par notre procédure de post-traitement (Postprocessed Output). Seules les prédictions ayant un score de confiance supérieur à
0,25 sont affichées (ce seuil a été sélectionné pour maximiser le score de précision/rappel (F1-score) sur l’ensemble de données de validation). Des versions de ces images à plus haute résolution sont montrées dans les figures A1–A4.
Fig. 3 : Performance stratifiée par années d’expérience autodéclarée en diagnostic des RPD (les lignes correspondent à la médiane, les boîtes couvrent l’écart entre le premier et le troisième quartile et les moustaches représentent la plage complète). Les groupes sont composés de neuf (? 4 années), six (4–8 années) et neuf (? 8 années) chirurgiens BMF, respectivement.
Fig. 4 : Comparaison entre les prédictions du modèle et celles des 24 chirurgiens BMF en termes de score de précision/rappel (F1-Score) pour l’ensemble de données de test. Le seuil du modèle a été choisi de sorte à maximiser le score de précision/rappel (F1-score) dans l’ensemble de données de validation. Les écarts moyens quadratiques (moustaches et bandes d’incertitude) ont été calculés par une analyse jackknife.
Fig. 5 : Comparaison entre la performance du modèle et celle des 24 chirurgiens BMF pour l’ensemble de données de test. Les écarts moyens quadratiques (moustaches) ont été calculés par une analyse jackknife. La courbe représentant un F1-Score constant de 0,58 est utilisée pour comparer les résultats de performance de la figure 3.
Fig. 6 : Comparaison des classements des scores de confiance relatifs aux cas positifs (gauche) et aux cas négatifs (droite) produits par le modèle (modèle d’apprentissage profond annoté sur l’axe) et la cohorte de chirurgiens BMF (cohorte de chirurgiens BMF annotée sur l’axe). Les régions d’intérêt qui ont été indiquées comme étant le plus (moins) probablement une radioclarté périapicale occupent le rang le plus haut (bas).
2.4. Caractéristiques de référence utilisées pour la sélection et l’évaluation du modèle
Un lot particulier de 197 RPD et des diagnostics associés a été obtenu dans le service de chirurgie buccale et maxillo-faciale, hôpital Charité, Berlin. Les caractéristiques de ces RPD ont servi de données de référence pour la sélection du modèle et les objectifs d’évaluation finaux. Les images et les annotations étaient celles d’un chirurgien BMF indépendant de l’étude, possédant sept années d’expérience. Les diagnostics avaient été établis par le chirurgien BMF, qui avait pris et évalué la radiographie de chaque patient, puis effectué un examen clinique intra-oral de chaque dent des patients par des tests de vitalité (thermiques et percussion).
Les données ont été divisées en deux sous-ensembles au niveau du patient : un ensemble de validation de 95 images qui a été utilisé pour la sélection du modèle, et un ensemble de test de 102 images (tel que décrit dans la section 2.1 de matériel et méthodes) qui a été utilisé pour l’évaluation finale de notre modèle après son entraînement.
La figure 1 présente les répartitions des radio-clartés péri-apicales pour chacun des deux ensembles, ainsi que pour l’ensemble de données d’entraînement.
2.5. Test de performance de référence utilisé pour la comparaison du modèle
La performance du modèle a été comparée avec un test de performance de référence effectué par 24 chirurgiens BMF. Les protocoles de diagnostic des images ont été les mêmes que ceux fournis par le chirurgien BMF qui avait annoté les ensembles de données d’entraînement, sauf que les chirurgiens BMF participant à l’étude ont été invités à indiquer un point unique au centre de chaque radio-clarté péri-apicale plutôt que de délimiter un contour strict.
2.6. Modèle
Nous avons présenté la tâche de détection des radio-clartés périapicales comme un problème de classification dense, où chaque pixel d’une image radiographique en entrée contient une radio-clarté périapicale ou n’en contient pas (voir Annexe A pour les détails complets). Le modèle reposait sur un réseau de neurones à convolution profonds pour la segmentation d’images,(37) dont le résultat en sortie était une carte d’intensité indiquant les régions contenant une radio-clarté périapicale à laquelle un score élevé ou faible de confiance était attribué. Ces cartes d’intensité ont fait l’objet d’un traitement subséquent pour produire une liste de sites ponctuels de radio-clarté péri-apicale dans l’image et de leurs scores de confiance [0] ou [1]. (Figures 2 et A1, figures A2–A5).
2.7. Métriques d’évaluation
La performance de notre modèle a été évaluée en termes de valeur prédictive positive (généralement appelée « précision »), VPP = NTP/(NTP + NFP), le taux de vrais positifs (généralement appelé « sensibilité » ou « rappel »), TVP =NTP/(NTP + NFN), et de F1-Score (un score généralement utilisé pour mesurer la performance lors de l’apprentissage machine, défini comme la moyenne harmonique de la VPP (précision) et du TVP (sensibilité/rappel), où NTP est le nombre de vrais positifs (VP), NFP est le nombre de faux positifs (FP) et NFN est le nombre de faux négatifs (FN) pour les prédictions sur l’ensemble des données considérées (voir l’Annexe A pour les détails complets). Le modèle a également été évalué à l’aide de la précision moyenne (PM), définie comme l’aire sous la courbe VPP – TVP selon la somme de Riemann. Les métriques de la performance ont été déterminées en fonction d’un seuil de confiance, en considérant les sites avec des scores de confiance supérieurs au seuil comme des prédictions positives.
2.8. Évaluation des corrélations entre la performance du modèle et celles des chirurgiens BMF
En plus des métriques traditionnelles d’évaluation et des comparaisons avec le test de performance de référence, nous avons étudié la relation entre les scores de confiance de notre modèle et ceux déduits de la cohorte des 24 chirurgiens BMF. Les sites identifiés par les 24 chirurgiens BMF comme étant une radio-clarté péri-apicale dans l’ensemble de données de test ont été partitionnés manuellement par un chirurgien BMF, selon les sites de radio-clarté péri-apicale correspondant aux caractéristiques de référence, ou selon le site radiculaire en l’absence de radio-clartés. Une zone de contour a ensuite été produite autour de chaque partition et un score de confiance de la cohorte a été attribué à chaque région en fonction de la proportion de chirurgiens BMF ayant considéré la région comme une radio-clarté péri-apicale. Pour les besoins de la comparaison, nous avons en outre déterminé un score de confiance du modèle en fonction de ses prédictions au sein de chaque région. Nous avons finalement utilisé le coefficient de corrélation de rang de Spearman pour évaluer la relation monotone entre les scores de confiance du modèle et de la cohorte.
3. Résultats
3.1. La fiabilité des diagnostics de présence d’une radio-clarté péri-apicale établis par les chirurgiens BMF sur les RPD
Au total, 2 448 images (102 images par chirurgien BMF, pour 24 chirurgiens BMF) ont été annotées dans cette étude. Selon les résultats de cette analyse (Tableau 2), la VPP moyenne des chirurgiens BMF pour cette tâche de détection des radio-clartés sur les RPD correspondait à 0,69 (± 0,13), indiquant qu’en moyenne, le diagnostic positif établi dans 31 % des cas était erroné (erreur de type I). Le taux moyen de vrais positifs (TVP) dans l’ensemble des chirurgiens BMF correspondait à 0,51 (± 0,14), indiquant qu’en moyenne, ils étaient passés à côté de 49 % des radio-clartés (erreur de type II). La performance des chirurgiens BMF était significativement inférieure en termes de TVP par rapport à la VPP ) selon le test non paramétrique de Wilcoxon pour observations appariées (p = 0,003). D’après la distribution des performances (Tableau 2), la probabilité que les chirurgiens BMF aient une VPP supérieure à 0,5 était de 96 (± 4) % tandis que la probabilité qu’ils aient un TVP supérieur à 0,5 n’était que de 50 (± 10) %, les valeurs indiquées entre parenthèses représentant un intervalle de 1 écart-type (1?) dans la plage des incertitudes associées aux estimations statistiques.
Tableau 2 : Métriques de la performance de chaque chirurgien BMF, d’après leur évaluation de 102 images radiographiques (2 248 images lues au total) et la réponse donnée à l’examen. Descriptifs des colonnes : A : Années d’expérience en analyse des RPD (répartition en trois groupes de taille à peu près égale) ; B : temps médian passé par image (secondes) ; C : heures de travail avant la tâche. L’incertitude 1 concernant la VPP et le TVP de chaque chirurgien-dentiste varie de 0,03 à 0,06.
La relation entre l’expérience en diagnostic des radio-clartés péri-apicales et la performance est représentée sur la figure 3, dans laquelle les chirurgiens BMF ont été répartis en trois groupes de taille à peu près égale ( 4 années, 4–8 années, et 8 années). Dans le diagramme, la performance moyenne semble indiquer l’absence d’un effet significatif sur la VPP ou le TVP dû à l’expérience.
3.2. Performance de l’algorithme d’apprentissage profond
La comparaison entre la performance du modèle et celle des 24 chirurgiens BMF en termes de score de précision/rappel (F1-Score) est présentée sur la figure 4. Pour ce qui est de cette métrique, nous avons constaté que le modèle surpasse 14 des 24 chirurgiens BMF (58 % des chirurgiens BMF) au seuil de confiance de 0,25 relatif à la meilleure performance, déterminé au moyen de l’ensemble de données de validation. Le modèle a obtenu une précision moyenne (PM) de 0,60 (± 0,04) et un score de précision/ rappel (F1-Score) de 0,58 (± 0,04) correspondant à une VPP de 0,6 (± 0,05) et un TVP de 0,51 (± 0,05), dont les écarts moyens quadratiques indiqués entre parenthèses ont été déterminés à l’aide d’une analyse jackknife (couteau suisse). Ces résultats de performance sont conformes aux valeurs moyennes de la VPP et du TVP mesurées pour la cohorte des 24 chirurgiens BMF. La performance du modèle (VPP en fonction du TVP, aussi couramment appelée courbe de précision-rappel) est présentée à la figure 5, et comparée avec le test de performance de référence effectué par les 24 chirurgiens BMF. La courbe et l’écart moyen quadratique ont été déterminés par une modélisation paramétrique de la VPP et du TVP en fonction du seuil de confiance. En particulier, lorsque le seuil de confiance disparaît, la VPP disparaît aussi, mais le TVP atteint une valeur maximale d’environ 0,9.
Par contre, lorsque le seuil de confiance se rapproche de l’unité, la VPP se rapproche aussi de l’unité, mais aux dépens d’une diminution du TVP. Le seuil optimal est défini en fonction de l’utilisateur et dépend de facteurs extérieurs tels que les risques relatifs pour la santé et les coûts associés à un excès de faux positifs (FP) par rapport à un excès de faux négatifs (FN). Il convient de noter que le modèle a surpassé la performance de la moitié environ des 24 chirurgiens BMF (c.-à-d., ceux dont la VPP et le TVP se situent au-dessous et à gauche de la courbe du modèle sur la figure 5) dans la mesure où, pour ces chirurgiens BMF, on observe en permanence un seuil de confiance pour lequel le modèle présente une meilleure performance en termes de VPP et de TVP.
La corrélation entre le classement des scores de confiance du modèle et de la cohorte de chirurgiens BMF est illustrée séparément à la figure 6 pour les cas positifs (présence de radio-clarté péri-apicale) et les cas négatifs (absence de radio-clarté péri-apicale) identifiés par la cohorte de chirurgiens BMF. Pour les cas positifs, la corrélation de Spearman correspond à 0,72 (valeur p : < 0,001), alors que pour les cas négatifs, elle est de 0,34 (valeur p : < 0,001). La corrélation positive indique que les scores de confiance du modèle tendent à augmenter de façon monotone avec les scores de confiance de la cohorte. Curieusement, cette corrélation semble significativement plus forte pour les cas positifs que pour les cas négatifs. Cette valeur plus élevée de la corrélation pour les cas positifs semble indiquer que le modèle et la cohorte de chirurgiens BMF détectent plus facilement ou difficilement les mêmes types de radio-clartés péri-apicales. La corrélation plus faible pour les cas négatifs évoque cependant une meilleure complémentarité entre le modèle et la cohorte pour ces cas.
4. Discussion
Alors que les progrès en radiologie numérique ont été une priorité majeure de la recherche médicale ces dernières anées, il n’en a pas été de même en dentisterie. Bien que les chirurgiens BMF lisent généralement leurs RPD, notre étude démontre que leur aptitude à identifier les radio-clartés péri apicales sur les panoramiques dentaires est insuffisante. Spécifiquement, les résultats semblent indiquer que les chirurgiens peuvent passer à côté des radio-clartés périapicales et faire ainsi peser des risques sur les résultats des patients ou, dans le pire des cas, entraîner des décès dans un service d’urgence, ce qui finalement expose les chirurgiens BMF à d’importantes responsabilités.
D’après ces résultats, nous avons développé un algorithme d’apprentissage machine permettant l’identification de radio-clartés périapicales qui, non seulement est plus performant au niveau de certaines métriques que la moitié des chirurgiens BMF expérimentés impliqués dans notre comparaison, mais pourra aussi servir d’outil complémentaire pour la pose des diagnostics ainsi que de fondement pour une détection plus complète et entièrement automatisée des radio-clartés périapicales dans le futur.
Nos résultats concordent étroitement avec une recherche récemment publiée qui a décrit un algorithme de détection des radio-clartés apicales sur les RPD dans le cadre d’un traitement endodontique,33 avec un taux de vrais positifs (TVP) de 0,65 (± 0,12) et une valeur prédictive positive (VPP) de 0,49 (± 0,10). Le groupe menant cette recherche avait choisi une autre approche qui consistait à évaluer l’algorithme au moyen d’un ensemble de données annotées dans le cadre d’une entente inter évaluateurs regroupant six chirurgiens-dentistes. Les résultats pourraient donc être moins fiables que notre méthodologie, qui inclut une validation clinique croisée des radio-clartés péri-apicales annotées pour l’établissement de la vérité terrain. De plus, dans cette recherche, (33) les images avaient été annotées par des chirurgiens-dentistes qui avaient utilisé des radiographies péri-apicales pour le traitement endodontique plutôt que des RPD, et ceci pourrait limiter d’autant plus la fiabilité. En particulier, une évaluation finale de la performance du modèle sur un ensemble de données de test permanent (c.-à-d., un ensemble de données demeuré intact jusqu’à la fin du processus d’entraînement, du réglage hyper-paramétrique et de la sélection du modèle) n’a pas été réalisée.
Leurs résultats sont donc susceptibles de refléter un surapprentissage sur l’ensemble de données de validation. Bien que nos résultats soient prometteurs, cette étude comporte plusieurs limitations.
Premièrement, l’entraînement de notre algorithme s’est déroulé sur des données annotées par des chirurgiens BMF d’après les lectures de radiographies plutôt que des tests cliniques. Notre algorithme pourrait donc refléter les limitations et la subjectivité de ces chirurgiens BMF, et l’apprentissage de ces limitations et des subjectivités se traduirait par une diminution de la performance sur l’ensemble des données de test. Il importe de remarquer que de tels problèmes n’invalident pas notre étude puisque l’ensemble des données de test a été annoté sur la base des résultats de tests cliniques. Toutefois, il serait possible d’améliorer la performance en examinant ces questions de plus près. Quoiqu’il soit tentant de partir de l’hypothèse qu’un ensemble de données d’entraînement annoté par de nombreux évaluateurs devrait améliorer la situation, ceci peut ne pas être le cas si les limitations et les subjectivités de ces évaluateurs sont corrélées. Au vu de la forte corrélation observée entre les classements des scores de confiance de notre modèle et de la cohorte de 24 chirurgiens BMF qui ont lu les mêmes radiographies, il pourrait en effet y avoir des points qui sont communs aux vecteurs de mauvais diagnostic entre le modèle et la cohorte, et ceci mérite une étude plus poussée (p. ex., une étude de la performance du modèle et de la cohorte de chirurgiens BMF sur des sous-populations, comportant idéalement un ensemble de données de test beaucoup plus vaste). Une meilleure compréhension de ces vecteurs, qu’ils soient liés à la qualité des images, à des aspects inhérents aux radio-clartés péri-apicales (p. ex., niveau de progression) ou à des différences de formation, pourrait mieux renseigner sur le processus de collecte des données destinées à l’entraînement du modèle. Il convient toutefois de noter que, même avec des annotations de données d’entraînement cliniquement ou histologiquement validées, les problèmes peuvent persister.
Deuxièmement, bien que nous ayons évalué notre modèle au moyen d’annotations cliniquement validées pour établir la vérité terrain, on ne peut exclure une erreur d’annotation puisque ces tests cliniques comportent le risque d’une mauvaise interprétation, et dans notre cas, ils n’ont été réalisés que par un seul chirurgien BMF expérimenté.
Il est néanmoins possible de maîtriser cet aspect, par exemple en faisant réaliser de multiples tests cliniques sur le même patient par plusieurs chirurgiens BMF, mais ceci représenterait une entreprise coûteuse tant pour le patient que pour le chirurgien BMF. En dépit de cette limitation, nous pensons que le recours aux annotations fondées sur les tests cliniques est néanmoins préférable aux alternatives couramment utilisées, telles que l’entente inter-observateur, qui comporte des limitations et biais inhérents.
Enfin, bien que nous ayons testé notre algorithme sur un ensemble de données indépendant de 102 images comportant des annotations cliniquement validées, des tests supplémentaires seront requis pour démontrer la possibilité de généraliser notre modèle aux données collectées dans d’autres sites. Le problème ici retombe de nouveau sur la subjectivité susceptible d’être apprise à partir des données d’entraînement provenant d’une source unique (par exemple, si les modalités d’imagerie diffèrent d’un établissement à l’autre, ou si les populations de patients sont différentes).
Dans les prochaines études, un ensemble de données d’entraînement collecté auprès de plusieurs centres mènerait probablement à une meilleure robustesse de l’algorithme dans les différents centres. En général, un défi majeur des applications d’apprentissage machine en radiologie demeure la façon d’atteindre un niveau de performance surhumain. Dans ce travail, l’atteinte de tels niveaux de performance exigera un ensemble de données d’entraînement annotées plus vaste et de meilleure qualité. La littérature a montré que nous pourrions atteindre une telle performance en augmentant la taille de notre ensemble de données d’un facteur 10 à 100, et en multipliant les annotations du même ensemble de données d’entraînement par différents évaluateurs, ou en acquérant des annotations validées sur le plan clinique, et si cela est possible, sur le plan histologique pour l’ensemble des données d’entraînement.(38, 39)
Cependant, ces stratégies représenteraient un coût notable en raison de la quantité de ressources humaines compétentes requises. Il est important de noter toutefois que les diagnostics histologiques comportent aussi des limitations. Bien que dans ce cas, on prévoit une VPP égale à 1,0 (tous les cas diagnostiqués comme étant positifs sont réellement positifs), le TVP restera vraisemblablement inférieur à 1,0, car c’est au chirurgien- dentiste ou au chirurgien BMF de décider si un diagnostic histologique doit être établi ou pas. La présence d’une radio-clarté Péri-apicale ne le conduira pas automatiquement à l’extraction de la dent concernée pour obtenir des échantillons tissulaires aux fins d’une analyse histologique.
En l’absence d’une incitation (p. ex., une indication non remarquée par le dentiste sur une radiographie ou aucune déclaration de douleur par le patient) à entreprendre les tests nécessaires, la lésion peut ne pas être décelée. C’est pourquoi nous croyons à l’utilité d’une solution algorithmique pour augmenter la probabilité d’attirer l’attention sur la présence de lésions potentielles sur une radiographie, et d’inciter ainsi le chirurgien-dentiste/le chirurgien BMF à entreprendre d’autres tests.
On peut évidemment continuer à se demander pourquoi, dans cette étude, des RPD ont été utilisés pour diagnostiquer des radio clartés péri-apicales plutôt que, par exemple, des radiographies péri-apicales.
Les radio-clartés péri-apicales peuvent être détectées au moyen de diverses modalités d’imagerie, et les radiographies péri-apicales sont la norme pour les radiographies endodontiques.
Cependant, cette modalité ne dévoile qu’une seule dent, ou quelques-unes, et lors d’une comparaison avec une norme de référence (c.-à-d., un examen sur un cadavre ou un examen histologique), elle présente une faible performance discriminatoire. (40) La tomodensitométrie à faisceau conique (CBCT) est une modalité d’imagerie 3D qui a fait preuve de la meilleure performance discriminatoire.(41) Néanmoins, son utilisation est limitée en raison du coût élevé et de la dose de rayonnement associée à l’examen. Les RPD ont par contre un potentiel diagnostique discriminatoire relativement bon et permettent l’évaluation de toute la denture et des structures osseuses environnantes, tout en administrant des doses de rayonnement beaucoup plus faibles par rapport à la CBCT.(33–35) De nombreux chirurgiens-dentistes généralistes et chirurgiens BMF choisissent donc la radiographie panoramique en raison de ses avantages.(33)
L’intelligence artificielle peut améliorer les résultats cliniques et valoriser l’imagerie médicale à des niveaux bien au-delà de notre imagination. Surtout en imagerie médicale, l’AI évolue rapidement de la phase expérimentale vers la phase d’application.
Étant donné les progrès majeurs dans la reconnaissance d’image grâce à l’apprentissage profond, on pourrait supposer que le rôle du radiologue perdra bientôt de son importance.
Toutefois, cette hypothèse ne tient pas compte des limitations réglementaires mises en place sur l’utilisation de l’AI dans le contexte clinique. Par exemple, à l’heure actuelle, la FDA et les responsables européens du marquage CE n’autorisent ce type de logiciel à titre de dispositif d’assistance.
Le travail complexe des radiologues comporte de nombreuses autres tâches qui requièrent du bon sens et une intelligence générale pour intégrer les concepts médicaux de diverses spécialisations cliniques et domaines scientifiques, et l’AI n’en est pas encore é ce niveau.
En plus des barrières réglementaires, l’impact de l’AI sur la dentisterie et toute autre spécialisation dépendra des interactions entre l’homme et la machine. Il subsiste des questions sur la probabilité qu’un expert accepte la suggestion d’un algorithme et réalise des tests supplémentaires.
Comment la présentation de la prédiction de l’AI influe-t-elle sur la réponse d’un expert ? Les patients feraient-ils confiance à des algorithmes ? Comment les réponses à ces questions varient-elles selon les cultures, ou selon le temps à mesure que la confiance dans l’AI s’élève ? Nous ne prétendons pas traiter ces questions dans cette étude, mais la compréhension de ces aspects sera importante pour l’avenir de l’AI en imagerie médicale.
5. Conclusions
Dans cette étude, nous avons démontré qu’un modèle d’apprentissage profond entraîné sur un ensemble de données minutieusement sélectionné et préparé à partir de 2 902 images radiographiques anonymisées peut égaler la performance diagnostique moyenne de 24 chirurgiens BMF dans la détection des radio-clartés péri-apicales. La VPP moyenne des chirurgiens BMF s’élevait à 0,69 (± 0,13) et leur TVP moyen sur un ensemble de données de test permanent de 102 radiographies était de 0,51 (± 0,14). À titre comparatif, la VPP du modèle s’élevait à 0,67 (± 0,05) et son TVP à 0,51 (± 0,05), ce qui correspondant à un score de précision/rappel (F1-Score) de 0,58 (± 0,04). La précision moyenne (PM) du modèle était de 0,60 (± 0,14). La corrélation de rang entre les scores de confiance du modèle et de la cohorte pour les cas positifs et les cas négatifs était de 0,72 et 0,34, respectivement.
L’AI est sur le point de devenir un atout précieux pour les professionnels de la santé. Bien que des recherches plus poussées soient nécessaires pour résoudre la myriade de questions encore ouvertes, notre travail représente un premier pas prometteur vers la conception d’un outil d’assistance reposant sur l’apprentissage machine pour la profession dentaire, un outil capable de rivaliser avec les chirurgiens BMF dans la détection des radio-clartés péri-apicales basée sur l’évaluation visuelle des radiographies.
Dans la mesure où l’AI prend de plus en plus d’importance dans les soins de santé, nous avons bon espoir que les organismes de soins de santé ajusteront leurs pratiques de collecte des données de façon à mieux s’aligner sur les besoins de l’apprentissage machine.
Un tel comportement permettra finalement d’ouvrir la voie à l’apprentissage en ligne (avec des modèles qui apprennent et s’améliorent continuellement) ainsi qu’au développement de modèles fusionnés avec les données qui associent les radiographies à d’autres informations des patients pour établir des diagnostics extrêmement fiables.
Contributions des auteurs :
R.A.G. : contributions importantes à la conception ou à l’élaboration du plan du travail et de l’acquisition, l’analyse et l’interprétation des données.
Préparation du travail.
L’auteur accepte la responsabilité de tous les aspects du travail en garantissant que les questions liées à la précision ou à l’intégrité de toute partie du travail seront pertinemment examinées et résolues ou revues avec un regard critique quant au contenu intellectuel important ; approbation finale de la version à publier ; et prise de la responsabilité de tous les aspects du travail en garantissant que les questions liées à la précision ou à l’intégrité de toute partie du travail seront pertinemment examinées et résolues. M.G.E. : contributions importantes à la conception ou à l’élaboration du plan du travail et de l’acquisition, l’analyse et l’interprétation des données.
Préparation du travail.
Revue avec un regard critique du contenu intellectuel important et approbation finale de la version à publier. F.H. : contributions importantes à la conception ou à l’élaboration du plan du travail et de l’acquisition, l’analyse et l’interprétation des données. Préparation du travail.
M.S. : contributions importantes à l’acquisition et l’interprétation des données. B.B.-B. : contributions importantes à l’acquisition et l’interprétation des données. C.R. : contributions importantes à l’acquisition et l’interprétation des données. S.M.N. : contributions importantes à l’acquisition et l’interprétation des données. O.Q. : contributions à l’acquisition des données. Revue avec un regard critique du contenu intellectuel important et approbation finale de la version à publier. H.H. ; contributions à l’acquisition des données. Revue avec un regard critique du contenu intellectuel important et approbation finale de la version à publier.
R.S. : contributions à l’acquisition des données. Revue avec un regard critique du contenu intellectuel important et approbation finale de la version à publier. M.H. : revue avec un regard critique du contenu intellectuel important et approbation finale de la version à publier. K.L. : revue avec un regard critique du contenu intellectuel important et approbation finale de la version à publier. A.R.S. : revue avec un regard critique du contenu intellectuel important et approbation finale de la version à publier.
Tous les auteurs ont lu et accepté la version publiée du manuscrit.
Financement :
M.G.E. a reçu une subvention de la fondation Eric and Wendy Schmidt Family Foundation.
Remerciements :
Les auteurs tiennent à remercier les 24 chirurgiens-dentistes qui ont participé à cette étude, ainsi que Neil Thompson, et Eva Guinan, pour leur lecture attentive du manuscrit et leurs commentaires.
Conflit d’intérêts :
F.H. est le directeur d’une entreprise qui développe des algorithmes pour la dentisterie. K.L. siège au conseil d’administration. Les autres auteurs, R.A.G., M.G.E., M.H., O.Q., R.S., S.M.N., A.R.S., B.B.B., C.R., M.S. et H.H., déclarent n’avoir aucun conflit d’intérêts potentiel.
Annexe A
Annexe A.1. Matériel et méthodes
Annexe A.1.1. Modèle
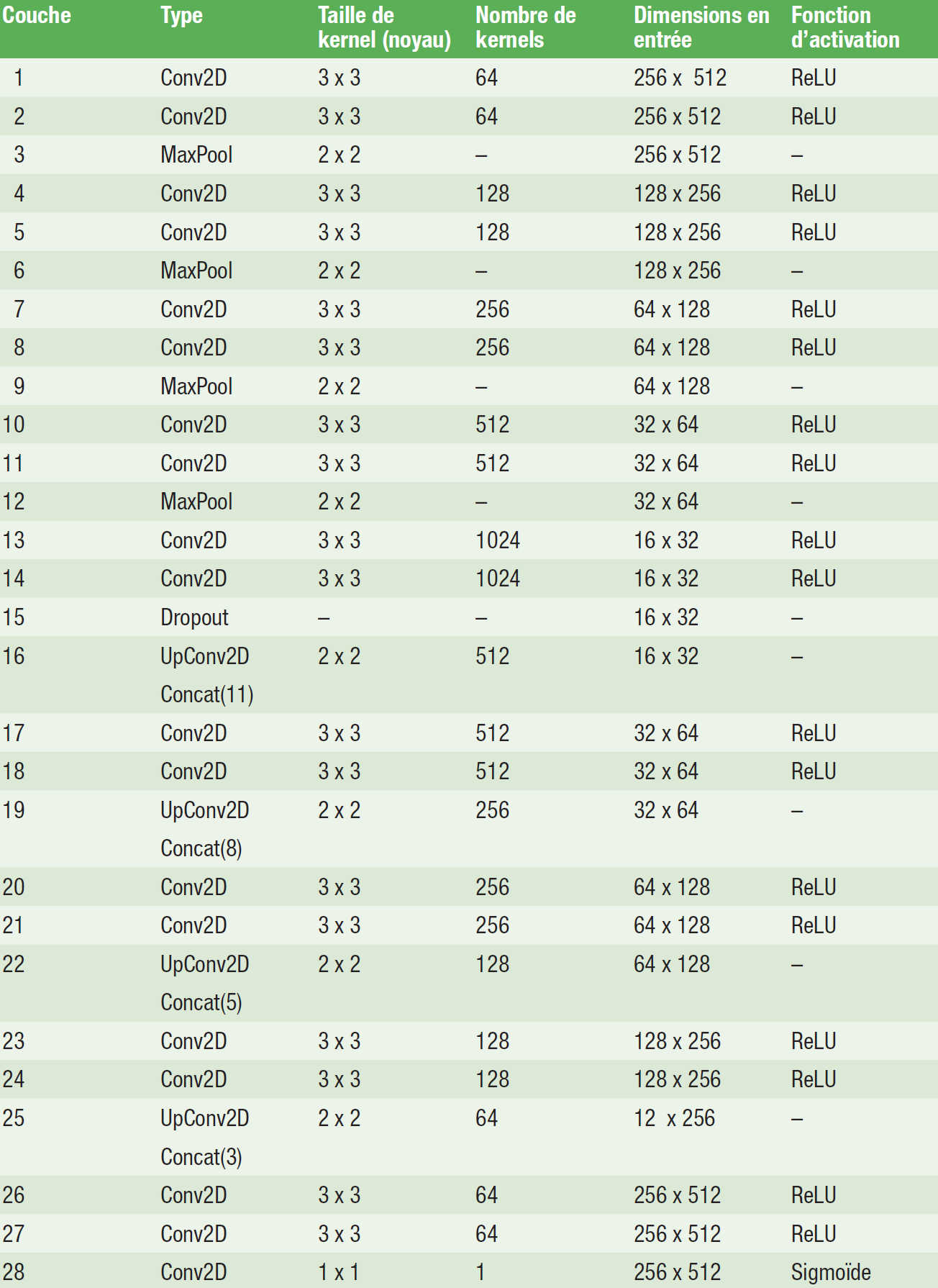
Tableau A1 : U-Net architecture. Légende : Conv2D : couche à convolution bidimensionnelle ; MaxPool : couche de Max-Pooling ; UpConv2D : couche à convolution transposée bidimensionnelle ; Concat(k) : concaténation des canaux avec sortie de la couche k.
Nous avons présenté la tâche comme un problème de classification dense, où chaque pixel de l’image contient une radio-clarté péri-apicale (cas positif) ou n’en contient pas (cas négatif). Nous avons utilisé une architecture de modèle fondée sur U-Net37 : même paramètre de remplissage (padding) des couches à convolution, cinq niveaux de résolution, couches de normalisation par lots42 introduite avant chaque couche d’activation (Tableau A1). L’utilisation de cette architecture a été dictée par le résultat d’un concours d’innovation libre, tenu sur TopCoder.com, Wipro, Bengaluru, Inde. Le réseau acceptait en entrée des images RPD prétraitées de 256 X 512 pixels dans l’intervalle [0,1],256 X 512 et en sortie une carte d’intensité dans l’intervalle [0,1],256 X 512 où les intensités des pixels proches de l’unité indiquaient des régions de cas positif avec un niveau élevé de confiance. Le prétraitement impliquait le redimensionnement des images radiographiques originales, dont la forme était variable, en une forme de référence (1 280 x 2 560 pixels), suivi par le recadrage des bords de l’image (100 pixels sur les bords supérieur et inférieur, et 300 pixels sur les bords gauche et droit), et enfin un redimensionnement des images recadrées en une forme cible standard de 256 x 512 pixels. Le redimensionnement a été effectué au moyen d’une interpolation bilinéaire. Les intensités des pixels des images ont ensuite été ajustées à l’intervalle [0,1].
Le modèle a été entraîné sur sept huitièmes de l’ensemble de données d’entraînement (le huitième restant a été utilisé pour la validation, p. ex., pour vérifier le surapprentissage) à l’aide d’une fonction d’objectif basée sur la fonction de perte selon le coefficient de Dice43 avec augmentation des données, incluant des transpositions aléatoires dans les directions horizontales et verticales (jusqu’à ± 20 pixels dans chaque direction), des inversions et des rotations horizontales (jusqu’à ±15 degrés). Les images ont été augmentées avec une probabilité de 50 % à chaque visite durant l’entraînement.
Le modèle a été entraîné au moyen de la méthode d’optimisation Adam (44) pendant 25 époques et en mini lots de dix images. Le taux d’apprentissage initial était de 0,001 et il a ensuite été réduit selon une décroissance exponentielle avec une constante de décroissance de 0,1/époque.
Les hyperparamètres du modèle ont été sélectionnés d’après la meilleure performance sur l’ensemble de données de validation. L’entraînement du modèle a été réalisé au moyen de l’accélérateur GPU Nvidia Tesla K80.
Un modèle d’ensemble a alors été créé en combinant les prédictions de dix modèles entraînés, chaque modèle ayant été entraîné au moyen des mêmes hyperparamètres sélectionnés et pendant la même période d’entraînement, comme décrit précédemment.
Chacun des modèles individuels a cependant été entraîné sur neuf de dix sous-ensembles disjoints de l’ensemble de données d’entraînement, divisés aléatoirement au niveau des patients. Une carte d’intensité d’ensemble a finalement été élaborée en prenant le résultat moyen produit en sortie par les dix modèles individuels.
Annexe A.1.2. Inférence et post-traitement
La sortie de notre modèle d’ensemble a fait l’objet d’un post-traitement avant l’évaluation (Figures A1–A4). Un filtre gaussien (largeur de trois pixels) a d’abord été appliqué à la carte d’intensité de 256 x 512 pixels en sortie pour atténuer toute variation ultra-locale ; ensuite, un algorithme de recherche de pic a été utilisé pour déterminer tous les maximums locaux et les scores de confiance associés.
Fig. A1 : Exemple 1 d’un RPD (prétraité pour l’entrée du modèle) choisi dans l’ensemble de données de test et superposé aux contours de la vérité terrain (Ground Truth), la carte d’intensité en sortie produite par notre modèle (Model Output) et les sites produits par notre procédure de post-traitement (Postprocessed Output). Seules les prédictions ayant un score de confiance supérieur à 0,25 sont affichées en exemple (ce seuil a été sélectionné pour maximiser le score de précision/ rappel (F1-score) sur l’ensemble de données de validation).
A2 : Exemple 2 ; voir la figure A1 pour les détails.
Fig. A3 : Exemple 3 ; voir la figure A1 pour les détails.
Fig. A4 : Exemple 4 ; voir la figure A1 pour les détails.
Fig. A5 : Exemple d’un RPD prétraité choisi dans l’ensemble de données de test et superposé aux contours de la vérité terrain (lignes continues) et aux régions de tolérance d’erreur de quatre pixels (lignes pointillées).
Ces derniers ont été définis comme étant la valeur de la carte d’intensité au niveau de chaque maximum local. L’algorithme de recherche de pic consistait à appliquer à la carte d’intensité un filtre maximum caractérisé par une taille (ou rayon) du voisinage correspondant à quatre pixels, puis à identifier les points (pics) pour lesquels l’image filtrée était égale à l’image originale. Nous avons choisi cette taille du voisinage pour le filtre maximum car nous avions observé que l’ensemble de données d’entraînement prétraité ne contenait qu’une proportion maximale de 0,5 % d’images présentant une distance centroïde minimale inférieure à quatre pixels entre les lésions.
Annexe A.1.3. Métriques d’évaluation
La performance de notre algorithme a été évaluée en termes de VPP, TVP, score de précision/ rappel (F1-Score) et de précision moyenne (PM), qui dépendent des nombres de vrais positifs (NTP), faux positifs (NFP) et faux négatifs (NFN) en fonction du seuil. Les prédictions pour un seuil donné ont été définies comme étant le sous-ensemble de sites de pic détectés dans la carte d’intensité en sortie, ayant des scores de confiance supérieurs au seuil spécifié. Pour un ensemble de prédictions donné, NTP a été défini comme étant le nombre total de régions positives se trouvant dans une tolérance d’erreur fixée à moins de quatre pixels (un choix conservateur reposant sur la distance typique inter-radiculaire ; voir figure A5) ou à la moitié de la distance minimale entre les contours situés dans l’image si plusieurs lésions étaient présentes (à noter que selon cette définition, les régions voisines contenant des erreurs ne se chevauchent jamais).
L’introduction de cette tolérance d’erreur était nécessaire pour tenir compte de la variabilité inhérente à l’interprétation de la région d’intérêt par le chirurgien BMF qui a effectué les annotations, notant que les contours de la vérité terrain ont été tracés de façon très stricte. NFN a été défini comme étant le nombre de régions d’intérêt positives sans aucun point candidat situé dans la tolérance d’erreur spécifiée. NFP a été défini comme étant le nombre total de points candidats situés à une distance supérieure à la tolérance d’erreur spécifiée de toute région d’intérêt.
Liste des auteurs : Michael G. Endres,1 Florian Hillen,1, 2 Marios Salloumis,3 Ahmad R. Sedagha,4 Stefan M. Niehues,5 Olivia Quatela,6 Henning Hanken,6 Ralf Smeets,6 Benedicta Beck-Broichsitter,3 Carsten Rendenbach,3 Karim Lakhani,1, 7 Max Heiland3 et Robert A. Gaudin1,
LEIPZIG, Allemagne : Dans les années 1980, le VIH – responsable du sida - a modifié la pratique des soins bucco-dentaires. Aujourd'hui, 40 ans plus ...
TORONTO, Canada/LONDRES, Royaume-Uni : Alors que la quête de dents plus blanches se poursuit, il est crucial de bien comprendre l'étendue des dommages que...
Quel que soit le degré de propreté et de stérilité de votre cabinet dentaire, il est quasiment illusoire d'espérer échapper à la contamination lors ...
HELSINKI, Finlande : Planmeca est ravie d’annoncer une coopération stratégique avec BEGO, pionnier renommé de la technologie CAD/CAM qui possède plus ...

 International / International
International / International
 Brésil / Brasil
Brésil / Brasil
 Canada / Canada
Canada / Canada
 Amérique latine / Latinoamérica
Amérique latine / Latinoamérica
 États-Unis / USA
États-Unis / USA
 Autriche / Österreich
Autriche / Österreich
 Bosnie Herzégovine / Босна и Херцеговина
Bosnie Herzégovine / Босна и Херцеговина
 Bulgarie / България
Bulgarie / България
 Croatie / Hrvatska
Croatie / Hrvatska
 République tchèque et Slovaquie / Česká republika & Slovensko
République tchèque et Slovaquie / Česká republika & Slovensko
 Allemagne / Deutschland
Allemagne / Deutschland
 Grèce / ΕΛΛΑΔΑ
Grèce / ΕΛΛΑΔΑ
 Italie / Italia
Italie / Italia
 Pays-Bas / Nederland
Pays-Bas / Nederland
 Nordique / Nordic
Nordique / Nordic
 Pologne / Polska
Pologne / Polska
 Portugal / Portugal
Portugal / Portugal
 Roumanie & Moldavie / România & Moldova
Roumanie & Moldavie / România & Moldova
 Slovénie / Slovenija
Slovénie / Slovenija
 Serbie et Monténégro / Србија и Црна Гора
Serbie et Monténégro / Србија и Црна Гора
 Espagne / España
Espagne / España
 Suisse / Schweiz
Suisse / Schweiz
 Turquie / Türkiye
Turquie / Türkiye
 Royaume-Uni et Irlande / UK & Ireland
Royaume-Uni et Irlande / UK & Ireland
 Chine / 中国
Chine / 中国
 Inde / भारत गणराज्य
Inde / भारत गणराज्य
 Japon / 日本
Japon / 日本
 Pakistan / Pākistān
Pakistan / Pākistān
 Vietnam / Việt Nam
Vietnam / Việt Nam
 ANASE / ASEAN
ANASE / ASEAN
 Israël / מְדִינַת יִשְׂרָאֵל
Israël / מְדִינַת יִשְׂרָאֵל
 Algeria, Morocco & Tunisia / الجزائر والمغرب وتونس
Algeria, Morocco & Tunisia / الجزائر والمغرب وتونس
 Moyen-Orient / Middle East
Moyen-Orient / Middle East

 Prof. Roland Frankenberger Univ.-Prof. Dr. med. dent.Webinaire en direct
Prof. Roland Frankenberger Univ.-Prof. Dr. med. dent.Webinaire en direct
 Dr. Corinne AttiaÀ la demande
Dr. Corinne AttiaÀ la demande Dr. Jean-Nicolas Hasson
Dr. Jean-Nicolas Hasson:sharpen(level=0):output(format=png)/up/dt/2014/02/Planmeca.png "Planmeca")
:sharpen(level=0):output(format=webp)/up/dt/2024/04/Dr-Renaud-Petibois-M-Dr-Gerard-Scortecci_R-Dr-Sepehr-Zarrine.jpg "EURO IMPLANTO monte sur scène pour son sixième congrès")
:sharpen(level=0):output(format=webp)/up/dt/2024/03/Printing-dental-restorations-now-possible-with-Planmeca-Creo-C5.jpg "L'impression de restaurations dentaires est désormais possible grâce à Planmeca Creo C5")
:sharpen(level=0):output(format=webp)/up/dt/2024/03/Best-Of-Implantology-2024-premieres-donnees-a-long-terme-sans-peri-implantite..jpg "Best Of Implantology 2024 : premières données à long terme sans péri-implantite")
:sharpen(level=0):output(format=webp)/up/dt/2024/03/Recycler-vos-attaches-.jpg "Recycler les attaches de blocs usinables usées aux profit des enfants hospitalisés")
:sharpen(level=0):output(format=webp)/up/dt/2024/03/ChatGPT-4.0-passes-dental-licensing-examinations.jpg "ChatGPT 4.0 réussit les examens de licence dentaire")
:sharpen(level=0):output(format=webp)/up/dt/2014/02/Planmeca.png "Planmeca")
:sharpen(level=0):output(format=webp)/up/dt/2011/07/fdi.png "FDI World Dental Federation")
:sharpen(level=0):output(format=webp)/up/dt/2014/02/3shape.png "3Shape")
:sharpen(level=0):output(format=webp)/up/dt/e-papers/338436/1.jpg "DT France No. 2, 2024")
:sharpen(level=0):output(format=webp)/up/dt/2024/02/DTF0124_01_Title.jpg "DT France No. 1, 2024")
:sharpen(level=0):output(format=webp)/up/dt/e-papers/330252/1.jpg "DT France No. 11, 2023")
:sharpen(level=0):output(format=webp)/up/dt/e-papers/328985/1.jpg "DT France No. 10, 2023")
:sharpen(level=0):output(format=webp)/up/dt/e-papers/327736/1.jpg "DT France No. 8+9, 2023")
:sharpen(level=0):output(format=webp)/up/dt/e-papers/323941/1.jpg "DT France No. 6+7, 2023")
:sharpen(level=0):output(format=webp)/up/dt/2021/02/D%C3%A9tection-des-pathologies-p%C3%A9ri-apicales-sur-les-radiographies-dentaires.jpg "Détection des pathologies périapicales sur les radiographies dentaires")

:sharpen(level=0):output(format=webp)/up/dt/2024/04/Dr-Renaud-Petibois-M-Dr-Gerard-Scortecci_R-Dr-Sepehr-Zarrine.jpg "EURO IMPLANTO monte sur scène pour son sixième congrès")
:sharpen(level=0):output(format=webp)/wp-content/themes/dt/images/no-user.gif "Michael G. Endres,1 Florian Hillen,1")
:sharpen(level=0):output(format=webp)/up/dt/2021/02/DTF-10-p9-01.jpg "Fig. 1 : Répartition par image des radioclartés périapicales pour l’ensemble de données.")
:sharpen(level=0):output(format=webp)/up/dt/2021/02/DTF-10-p9-02.jpg "Fig. 2 : Exemples d’RPD (prétraités pour l’entrée du modèle) sélectionnés à partir de l’ensemble de données de test et superposés aux contours des données de vérité terrain (Ground Truth), la carte d’intensité en sortie produite par notre modèle (Model Output) et les sites obtenus par notre procédure de post-traitement (Postprocessed Output). Seules les prédictions ayant un score de confiance supérieur à
0,25 sont affichées (ce seuil a été sélectionné pour maximiser le score de précision/rappel (F1-score) sur l’ensemble de données de validation). Des versions de ces images à plus haute résolution sont montrées dans les figures A1–A4.")
:sharpen(level=0):output(format=webp)/up/dt/2021/02/DTF-10-p9-03.jpg "Fig. 3 : Performance stratifiée par années d’expérience autodéclarée en diagnostic des RPD (les lignes correspondent à la médiane, les boîtes couvrent l’écart entre le premier et le troisième quartile et les moustaches représentent la plage complète). Les groupes sont composés de neuf (? 4 années), six (4–8 années) et neuf (? 8 années) chirurgiens BMF, respectivement.")
:sharpen(level=0):output(format=webp)/up/dt/2021/02/DTF-10-p9-04.jpg "Fig. 4 : Comparaison entre les prédictions du modèle et celles des 24 chirurgiens BMF en termes de score de précision/rappel (F1-Score) pour l’ensemble de données de test. Le seuil du modèle a été choisi de sorte à maximiser le score de précision/rappel (F1-score) dans l’ensemble de données de validation. Les écarts moyens quadratiques (moustaches et bandes d’incertitude) ont été calculés par une analyse jackknife.")
:sharpen(level=0):output(format=webp)/up/dt/2021/02/dtf-10-p9-05.jpg "Fig. 5 : Comparaison entre la performance du modèle et celle des 24 chirurgiens BMF pour l’ensemble de données de test. Les écarts moyens quadratiques (moustaches) ont été calculés par une analyse jackknife. La courbe représentant un F1-Score constant de 0,58 est utilisée pour comparer les résultats de performance de la figure 3.")
:sharpen(level=0):output(format=webp)/up/dt/2021/02/dtf-10-p9-06.jpg "Fig. 6 : Comparaison des classements des scores de confiance relatifs aux cas positifs (gauche) et aux cas négatifs (droite) produits par le modèle (modèle d’apprentissage profond annoté sur l’axe) et la cohorte de chirurgiens BMF (cohorte de chirurgiens BMF annotée sur l’axe). Les régions d’intérêt qui ont été indiquées comme étant le plus (moins) probablement une radioclarté périapicale occupent le rang le plus haut (bas).")
:sharpen(level=0):output(format=jpeg)/up/dt/2021/02/DTF-10-p9-01.jpg "Fig. 1 : Répartition par image des radioclartés périapicales pour l’ensemble de données.")
:sharpen(level=0):output(format=jpeg)/up/dt/2021/02/DTF-10-p9-02.jpg "Fig. 2 : Exemples d’RPD (prétraités pour l’entrée du modèle) sélectionnés à partir de l’ensemble de données de test et superposés aux contours des données de vérité terrain (Ground Truth), la carte d’intensité en sortie produite par notre modèle (Model Output) et les sites obtenus par notre procédure de post-traitement (Postprocessed Output). Seules les prédictions ayant un score de confiance supérieur à
0,25 sont affichées (ce seuil a été sélectionné pour maximiser le score de précision/rappel (F1-score) sur l’ensemble de données de validation). Des versions de ces images à plus haute résolution sont montrées dans les figures A1–A4.")
:sharpen(level=0):output(format=jpeg)/up/dt/2021/02/DTF-10-p9-03.jpg "Fig. 3 : Performance stratifiée par années d’expérience autodéclarée en diagnostic des RPD (les lignes correspondent à la médiane, les boîtes couvrent l’écart entre le premier et le troisième quartile et les moustaches représentent la plage complète). Les groupes sont composés de neuf (? 4 années), six (4–8 années) et neuf (? 8 années) chirurgiens BMF, respectivement.")
:sharpen(level=0):output(format=jpeg)/up/dt/2021/02/DTF-10-p9-04.jpg "Fig. 4 : Comparaison entre les prédictions du modèle et celles des 24 chirurgiens BMF en termes de score de précision/rappel (F1-Score) pour l’ensemble de données de test. Le seuil du modèle a été choisi de sorte à maximiser le score de précision/rappel (F1-score) dans l’ensemble de données de validation. Les écarts moyens quadratiques (moustaches et bandes d’incertitude) ont été calculés par une analyse jackknife.")
:sharpen(level=0):output(format=jpeg)/up/dt/2021/02/dtf-10-p9-05.jpg "Fig. 5 : Comparaison entre la performance du modèle et celle des 24 chirurgiens BMF pour l’ensemble de données de test. Les écarts moyens quadratiques (moustaches) ont été calculés par une analyse jackknife. La courbe représentant un F1-Score constant de 0,58 est utilisée pour comparer les résultats de performance de la figure 3.")
:sharpen(level=0):output(format=jpeg)/up/dt/2021/02/dtf-10-p9-06.jpg "Fig. 6 : Comparaison des classements des scores de confiance relatifs aux cas positifs (gauche) et aux cas négatifs (droite) produits par le modèle (modèle d’apprentissage profond annoté sur l’axe) et la cohorte de chirurgiens BMF (cohorte de chirurgiens BMF annotée sur l’axe). Les régions d’intérêt qui ont été indiquées comme étant le plus (moins) probablement une radioclarté périapicale occupent le rang le plus haut (bas).")

:sharpen(level=0):output(format=webp)/up/dt/2021/02/DTF-10-p9-A1.jpg "Fig. A1 : Exemple 1 d’un RPD (prétraité pour l’entrée du modèle) choisi dans l’ensemble de données de test et superposé aux contours de la vérité terrain (Ground Truth), la carte d’intensité en sortie produite par notre modèle (Model Output) et les sites produits par notre procédure de post-traitement (Postprocessed Output). Seules les prédictions ayant un score de confiance supérieur à 0,25 sont affichées en exemple (ce seuil a été sélectionné pour maximiser le score de précision/ rappel (F1-score) sur l’ensemble de données de validation).")
:sharpen(level=0):output(format=webp)/up/dt/2021/02/DTF-10-p9-A2.jpg "A2 : Exemple 2 ; voir la figure A1 pour les détails.")
:sharpen(level=0):output(format=webp)/up/dt/2021/02/DTF-10-p9-A3.jpg "Fig. A3 : Exemple 3 ; voir la figure A1 pour les détails.")
:sharpen(level=0):output(format=webp)/up/dt/2021/02/DTF-10-p9-A4.jpg "Fig. A4 : Exemple 4 ; voir la figure A1 pour les détails.")
:sharpen(level=0):output(format=webp)/up/dt/2021/02/DTF-10-9-A5.jpg "Fig. A5 : Exemple d’un RPD prétraité choisi dans l’ensemble de données de test et superposé aux contours de la vérité terrain (lignes continues) et aux régions de tolérance d’erreur de quatre pixels (lignes pointillées).")
:sharpen(level=0):output(format=jpeg)/up/dt/2021/02/DTF-10-p9-A1.jpg "Fig. A1 : Exemple 1 d’un RPD (prétraité pour l’entrée du modèle) choisi dans l’ensemble de données de test et superposé aux contours de la vérité terrain (Ground Truth), la carte d’intensité en sortie produite par notre modèle (Model Output) et les sites produits par notre procédure de post-traitement (Postprocessed Output). Seules les prédictions ayant un score de confiance supérieur à 0,25 sont affichées en exemple (ce seuil a été sélectionné pour maximiser le score de précision/ rappel (F1-score) sur l’ensemble de données de validation).")
:sharpen(level=0):output(format=jpeg)/up/dt/2021/02/DTF-10-p9-A2.jpg "A2 : Exemple 2 ; voir la figure A1 pour les détails.")
:sharpen(level=0):output(format=jpeg)/up/dt/2021/02/DTF-10-p9-A3.jpg "Fig. A3 : Exemple 3 ; voir la figure A1 pour les détails.")
:sharpen(level=0):output(format=jpeg)/up/dt/2021/02/DTF-10-p9-A4.jpg "Fig. A4 : Exemple 4 ; voir la figure A1 pour les détails.")
:sharpen(level=0):output(format=jpeg)/up/dt/2021/02/DTF-10-9-A5.jpg "Fig. A5 : Exemple d’un RPD prétraité choisi dans l’ensemble de données de test et superposé aux contours de la vérité terrain (lignes continues) et aux régions de tolérance d’erreur de quatre pixels (lignes pointillées).")
:sharpen(level=0):output(format=webp)/up/dt/2021/03/How-diseases-changed-standards-in-dentistry_780-x-439.jpg "Des pathologies qui modifient les normes de la pratique des soins dentaires")
:sharpen(level=0):output(format=webp)/up/dt/2024/03/Shutterstock_2425703171.jpg "L’ADA annonce des changements majeurs dans les protocoles de radiographie dentaire")
:sharpen(level=0):output(format=webp)/up/dt/2012/01/a0339a9a3666fe1d91a311189f2b5da3.jpg "Les radiographies dentaires peuvent prédire les fractures")
:sharpen(level=0):output(format=webp)/up/dt/2021/08/Quest-for-tooth-whitening-Study-reports-extensive-damage-to-dental-cells-by-carbamide-peroxide-.jpg "Blanchiment des dents : Les effets du peroxyde de carbamide sur les cellules dentaires")
:sharpen(level=0):output(format=webp)/up/dt/2024/01/New-journal-supplement-explores-the-role-of-mouthwash-in-oral-care.jpg "Le rôle des bains de bouche dans les soins bucco-dentaires")
:sharpen(level=0):output(format=webp)/up/dt/2020/01/img.jpg "Les nettoyants dentaires : des outils indispensables")
:sharpen(level=0):output(format=webp)/up/dt/2024/01/Study-emphasises-role-of-dental-professionals-in-screening-patients-for-chronic-disease.jpg "Étude sur le rôle des professionnels dentaires dans le dépistage des maladies chroniques")
:sharpen(level=0):output(format=webp)/up/dt/2017/01/a7606865f1d4f29b2936a32dec175252.jpg "Webinaire sur les bases biomécaniques du remodelage osseux autour des implants dentaires")
:sharpen(level=0):output(format=webp)/up/dt/2011/01/a1bce9c3a234ac330a49bf0e76144f9d.jpg "Les secrets des lasers dentaires enfin dévoilés")
:sharpen(level=0):output(format=webp)/up/dt/2011/09/b5386734884f73f20a7b3a07cecbc645-1.jpg "Un kit de détection aide les praticiens dentaires à voir les leucoplasies")











:sharpen(level=0):output(format=webp)/up/dt/2024/04/Dr-Renaud-Petibois-M-Dr-Gerard-Scortecci_R-Dr-Sepehr-Zarrine.jpg "EURO IMPLANTO monte sur scène pour son sixième congrès")
:sharpen(level=0):output(format=webp)/up/dt/2024/03/Printing-dental-restorations-now-possible-with-Planmeca-Creo-C5.jpg "L'impression de restaurations dentaires est désormais possible grâce à Planmeca Creo C5")
:sharpen(level=0):output(format=webp)/up/dt/2024/03/Best-Of-Implantology-2024-premieres-donnees-a-long-terme-sans-peri-implantite..jpg "Best Of Implantology 2024 : premières données à long terme sans péri-implantite")
:sharpen(level=0):output(format=webp)/up/dt/2024/02/DTF0124_01_Title.jpg "DT France No. 1, 2024")
:sharpen(level=0):output(format=webp)/up/dt/e-papers/330252/1.jpg "DT France No. 11, 2023")
:sharpen(level=0):output(format=webp)/up/dt/e-papers/328985/1.jpg "DT France No. 10, 2023")
:sharpen(level=0):output(format=webp)/up/dt/e-papers/327736/1.jpg "DT France No. 8+9, 2023")
:sharpen(level=0):output(format=webp)/up/dt/e-papers/323941/1.jpg "DT France No. 6+7, 2023")
:sharpen(level=0):output(format=webp)/up/dt/e-papers/338436/1.jpg "DT France No. 2, 2024")
:sharpen(level=0):output(format=webp)/up/dt/e-papers/338436/2.jpg "ISSUE")
:sharpen(level=0):output(format=webp)/wp-content/themes/dt/images/3dprinting-banner.jpg "3D Printing Banner")
:sharpen(level=0):output(format=webp)/wp-content/themes/dt/images/aligners-banner.jpg "3D Printing Banner")
:sharpen(level=0):output(format=webp)/wp-content/themes/dt/images/covid-banner.jpg "3D Printing Banner")
:sharpen(level=0):output(format=webp)/wp-content/themes/dt/images/roots-banner-2024.jpg "3D Printing Banner")
To post a reply please login or register